
VALOR
Tri-Modality Pretraining Model
Coherent Model Architecture
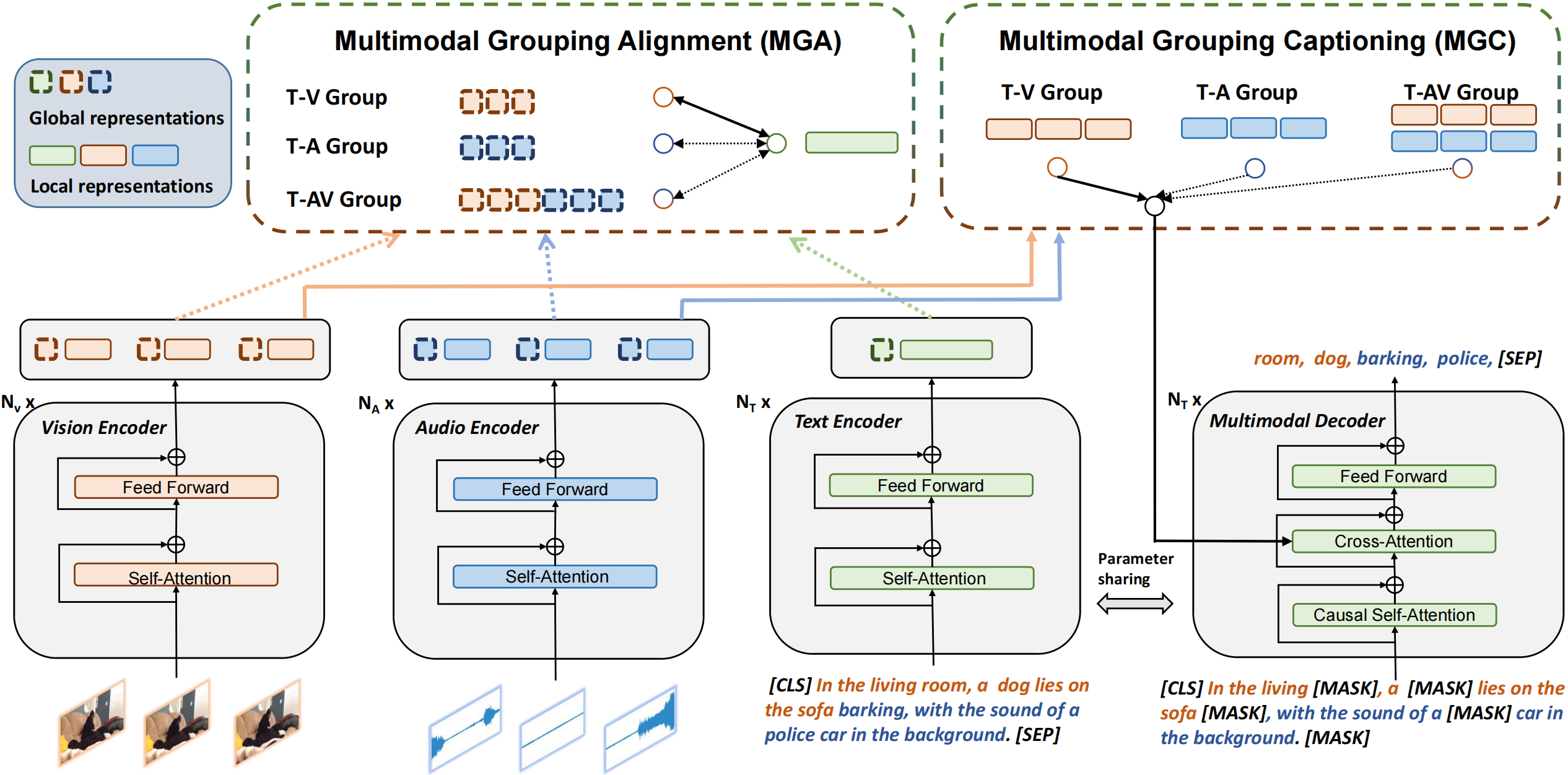
VALOR consists of separetely a text encoder , a vision encoder, an audio encoder and a multimodal decoder. Multimodal encoder partly share wwights with text encoder and has additional cross attention layers.
Broad Downstream Adaption
VALOR can be adapted to and is good at multiple cross-modality task type (e.g., retrieval , captioning and question answering), with different modality singals as input (e.g., vision-language, audio-language and audiovisual-language.)
Easily Scaling Up
All encoders and decoder in VALOR takes Transformer layers as basic building block which makes it easy to scale up via simply adjusting layer number and hidden size. Currently VALOR has two scales, named VALOR-B and VALOR-L. VALOR-B has 342M parameters and use 6.5M examples (VALOR-1M, WebVid-2.5M and CC3M) as training data. VALOR-L has 593M parameters and use 33.5M examples as training data. A more bigger version VALOR-H will soon be on the agenda.
Comprehensive Pretraining Objective
VALOR is pretrained under two designated pretext tasks, named Multimodal Grouping Alignment (MGA) and Multimodal Grouping Captioning (MGC). MGA builds vision-language, audio-language and audiovisual-language alignment simultaneously through grouped contrastive learning. MGC teaches model to conduct text generation in conditions of vision, audio or their both, via grouped causal masked language modeling.
VALOR has achieved 15+ new state-of-the-arts results on series of benchmarks!
On five text-to-video retrieval benchmarks, VALOR outperforms tasked-specified pretraining model including HunYuan_tvr, CLIP-VIP, and task-unified pretraining model like InternVideo.
With regards to video captioning benchmarks, VALOR achieves 95.8 CIDEr score on VATEX public test set, and surpasses GIT2 big model with only latter's 11.6% paramenters and 0.26% training data.
On five video question answering benchmarks, VALOR outperforms tasked-specified pretraining model like FrozenBiLM, and unified big models including GIT2, VideoCoCa and Flamingo, with extremely evident improvements.
